
一般像是 MySQL PostgreSQL 都是用 Btree 的方式建立索引。
注意:B-tree 不念 B減樹,而是直接念 Btree,所以如果看到 Btree vs B-tree 其實是在講同一個算法。
為什麼用 Btree
用二元樹進行查詢,最快的時間複雜度是 O(logN),以算法邏輯上面來說,二元樹搜尋的查找速度跟比較次數都是最小的,但是要注意的事,我們還需要考量一個現實的問題就是「硬碟 I/O」。
二元樹結構:
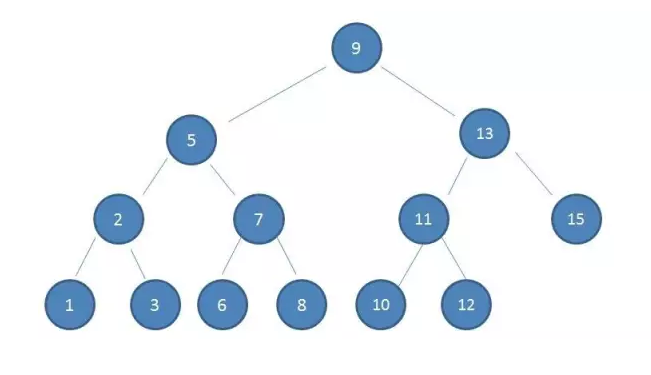
數據庫的索引都是儲存在硬碟上,當數據量龐大時,索引的大小可能會有幾 G 甚至更多。
我們不可能在透過索引查詢時,一次把幾 G 的索引快全部加載到內存裡,能做的就是逐漸加載每一個硬碟分頁,這裡的硬碟分頁對應著索引樹的節點。
二元樹在搜尋最差的情況下,樹的高度跟硬碟 I/O 次數會一樣,所以 B-tree 的特點就是把「瘦高」的結構變成「矮胖」,來降低 I/O 次數。
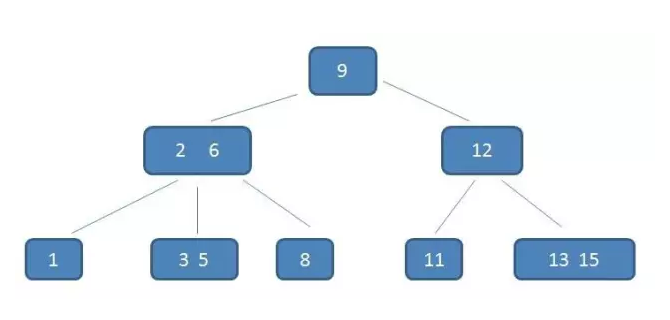
Btree 每個節點最多可以包容兩個值,如此一來就可以在節點內定位省了一次到不同硬碟分頁的時間。
Btree 結構:
哪裡用到 Btree
主要應用文件系統及部分的數據庫索引,比如非關連型數據庫 MongoDB
參考來源
-
如果你喜歡他的文章,歡迎回到他的部落格觀看更多:)
12/4 晚上由他擔任分享者的小聚活動,開放早鳥報名中,活動資訊請看下方連結:
學程式主題小聚 x Devstars Lighthouse|2個月擁有6000用戶,SideProject這樣做|Nic










