
延續上一篇:利用Airbnb來更了解臺北,這篇我們就要來把自己當成是Airbnb的資料科學家,嘗試建立房屋的訂價模型。
先說說流程:
- 檢查變數-價格相關性,好讓我們對影響變量有個了解
- 處理類別資料,轉換為Python的機器學習套件:Sklearn看得懂的東西
- 清理缺失值
- 切分資料成訓練、驗證集
- 利用交叉驗證建模,Baseline(基礎比較)我選擇L1、L2 Regression
- 建立Random Forest、XGboost Regressor
- 利用model畫出變數重要性,方便我們優化模型
- 反覆迭代,持續優化模型
- 結語,談如何優化與比較好的建模姿勢
這篇文章並不是一個「教你建立精準訂價的模型」的學術性文章,因為建立非常準確的模型是很花時間、又很費工夫的,一篇文章絕對寫不完,加上個人的時間有限,本篇處理變數與特徵的手法難免會粗糙一點(甚至最後還有嚴重的overfit),但是可以讓您一起做機器學習的模型,嘗試體驗一下訂價與逼近最優解的過程。準備好了,就打開電腦跟著一起做吧!
最下方也有完整的程式碼,做完可以參考看看哦!
看一下連續變數


“3:”意思是從第四個變數開始,因為前三個變數是id類型的變數,雖然Airbnb的訂價走向個人化了,id應該也藏著一些能夠讓機器學習的特徵,但這邊為了簡單一點,我們就把不重複數量過多的id類型變數先剔除掉。
接下來畫出相關係數圖,我喜歡用熱點圖來方便看出變數之間的相關性。
看到price那行,我們可以發現guests included 以及accommodates跟price算是最相關的,這蠻符合直覺,也跟上一篇我們做探索性資料分析時得到的insight一致。
資料處理(Data preprocessing)
第一步還是清資料,將離群值、NaN值太多的變數刪掉。
另外重複值太多的變數也要刪掉,因為如果表現不出差異性,其實對模型的學習是沒什麼幫助的。就好像猜硬幣,左手跟右手如果沒有明顯的差異,很難判斷跟預測說哪一隻手「有硬幣」,其實機器學習的預測就是如此,我們要嘗試建立多個差異大的特徵,讓模型比較好判斷並做出決策。

因為價格從Box plot可以看到有太多離群值,所以我們踢除掉一部分的離群值。
方便起見直接把NaN值剔除掉,填補缺失值的方式很多,有重新建模、統計變量填補,甚至一些模型其實可以吃缺失值(其實就是把缺失也當作一種特徵),缺失值在實際場景中其實蠻常看到的,包括資料無法取得(客戶不願意填寫)、資料不存在、機器故障,根據真實場景會有不同、更有意義的填補方式,那這邊我們還是先刪掉就好。
記得我們上一篇有看到的amenities屬性嗎?它裡面是存放許多個文字資料的,因此我們還要對文字變量分詞與編碼,這部分利用詞頻統計就好囉!

CountVectorizer可以協助我們點名
做出來的結果會是下圖,就是看每個房源「有沒有這個配備」,有的話就是1,沒有則是0。

這是一個高達127個維度的DataFrame,物件真的很多很複雜啊….
接下來挑出根本沒有差異的變數,比如使用的資料都是臺北市,像是Country、Country code就都一樣了,對模型沒有幫助,可以踢除掉。

接下來因為像是True、False等資料是電腦看不懂的,他們只認數字,所以我們就把True編碼為1,False編碼為0,跟上面的文字資料轉換「有無」邏輯相通。
合併表格

將目前的DataFrame與剛剛的amenities表格合併在一起,可以看到變成一張168維度的大表格。
更細緻處理類別變數
從上面這張表我們也可以發現還有許多文字資料對不對?這些文字對我們的model來說是看不懂的,我們必須利用編碼(Encoder)的技術來轉換文字資料,讓它們變成數字。
簡單來說,如果我們發現類別變量之間沒有明顯的關係,那就可以用One hot encoding,如果存在某種Order關係,好比對衣服大小來說,衣服的S、L、XL是有意義的,對機票的價格來說,機票的頭等艙、商務艙、經濟艙是有意義的,那我們就可以用Label encoding。如果是發現不同level有更具備可解釋的差異,好比不同商品品種的「價格帶」具備差異(比如小米跟紅米同樣都是來自小米公司,但是他們針對的TA就不同,價格帶也有明顯差異),相比Label可以更好描述,那就可以用Target encoding,不過Target encoding有個小問題是可能會存在data leakage(特徵洩漏)的問題,比如統計好每種品類的平均價格,模型就可以間接得知價格的上下限是多少,所以使用的時候要蠻小心的,不要用到太細的target。
從上面的編碼介紹我們也可以看到,其實很難說「看到什麼就用什麼編碼」,一切都是端看「所分析、預測的目標」是什麼,才有不同的編碼含義。如果想了解更多「商業目標與機器學習」的內容,可以看我之前的這篇文章:領域專家?利用管理顧問的技巧做特徵工程。
更多常用的編碼技巧可以看這篇機器學習馬拉松的文:特徵工程的編碼技術
我這邊是這樣做的:
- host verifications : 刪去
- neighbourhood_cleansed : mean encoding
- property_type : mean encoding ,有明顯差異
- amenities :刪掉,已經轉one hot了
- room_type :label encoding (似乎存在order relationship)
- bed_type : label encoding (似乎存在order relationship)
- extra people : 轉換為連續變量
- calendar_update :轉換為連續變量
- calendar_last_scraped : 刪掉
- cancellation_policy : mean encoding
接下來針對上面的編碼,我們寫兩個函數來方便重複操作。
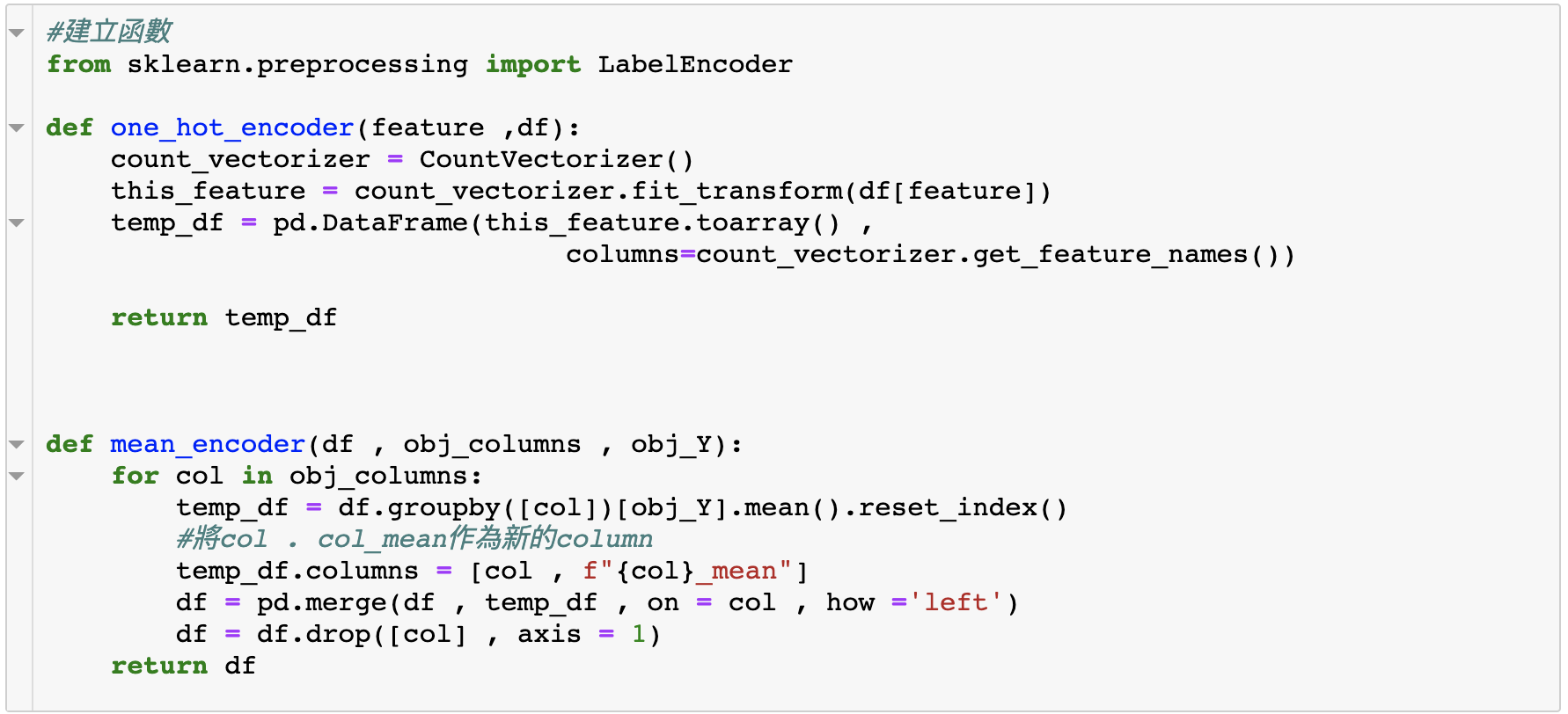

啊啊!還發現了仍然有些變數沒有差異性,所以再把他們刪除掉,當變數太多有時候還是會有漏網之魚,要小心檢查。
接下來處理extra people 、calendar_update :轉換為連續變量。
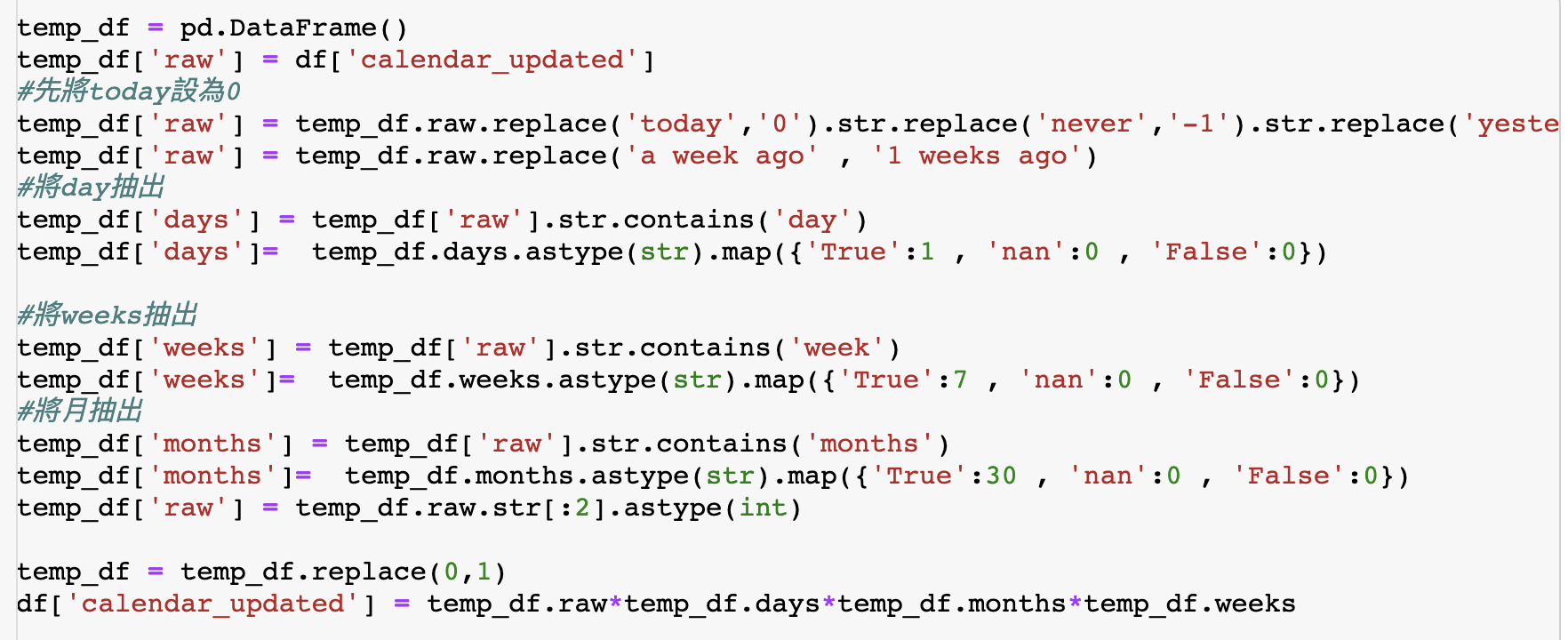
不過calendar update有點棘手,因為它的資料沒有徹底格式化,分成N週前、N天前、N月前,為了判斷時間,我們想把資料轉換為以天為單位的連續資料,而比較大的時間單位就乘上相對應的天數就好囉!
這邊的程式碼會比較複雜,腦袋打結的人可以直接複製貼上,或者想訓練處理時間資料的人可以自己練習寫寫看,如果換到Excel、PowerBI,又可以怎麼處理呢?可以好好想想哦!
清理缺失值
仔細看,我們發現extra people有少許缺失值,所以我們簡單用mode(眾數)填補。

建立訂價模型
這邊由於建模並非這份資料集的重點,因此我只會帶過基本的特徵處理、以及快速地建一個模型出來,也就是說這邊的model算是只做出一個baseline,如果要進行數據科學比賽,我個人的習慣還會搞剛許多、可能光是特徵工程就會分好幾篇來寫XXD
建模之前有些必須要做的資料處理,好比數據縮放,簡單的方式是直接把它標準化,因為有些演算法是基於距離的,如果距離的尺度相差太多,通常模型不會表現得很好,其中又有分為「最大最小縮放」與「標準化」。
通常我是使用標準化,這是因為許多線性模型中,比如Logistic regression (特別注意一下,Logistic regression是一個分類而不是迴歸模型),會初始化「加權」為0或者接近0的一個很小隨機值,使用標準化可以讓特徵縮放之後的平均值為0,標準差為1,特徵會滿足常態分佈,使得加權學習更容易完成。不過其實也要看面對什麼樣的資料以及問題,並沒有說哪個方法比較好,只有比較「適合目前的情況」而已。

接下來切分資料集,就好像讓資料變成隨堂測驗(train)與實際考試(test)。另外我們也把價格做對數轉換(取log),讓價格更接近常態分佈一些。

另外因為我們的變數實在太多了,其實可以在正式建模之前降維,將重要性不高的變數、高共線性的變數刪去,下面我有使用正則化(將重要性不高的變數自動剔除)來達到降維的效果,單純降維就不演示了,也可以用SBS 演算法來做,有興趣的朋友可以嘗試一下。
Baseline
我們使用L1、L2 Regression來做baseline,其中alphas是一個生成0.01~0.001(10的-2~-3次方)的矩陣,將之傳入model中,回傳的是alphas(正則懲罰係數)中各個數分別當作正則係數時的L2 model 。

我們可以引入LassoCV、RidgeCV,而不是單純的Lasso、Ridge模型,其實也跟考試的道理很像,我們總不會念完書、在學校考個段考就直接去考學測、指考(聯考),通常會有模擬考,仿真大考,可以讓我們檢視目前的程度並做應對,而CV(Cross validation)的道理也一樣,就是讓我們可以交叉驗證目前的實力如何並優化。

只是Baseline,這邊我們的模型解釋力(R square)只有52%。
隨機森林
如果是第一次看到這個演算法的人,這裡有隨機森林的簡單介紹。
簡單來說,就是利用Ensemble的方法將分類器們聚集在一起投票,使得模型具備解釋性的同時保持穩定。
接下來我們可以使用隨機森林建模,在Python中應用隨機森林相當簡單,只要引入Sklearn的ensemble models就好,簡單調整一下參數把資料放進去train。

RMSE下降到0.348,感覺其實不錯,再加入更多一點特徵能夠捕捉得更全面。另外可以畫出訓練資料的情形,會發現說R square相當高,此時就要小心overfit!這是因為我們給的變數太多了,比較好一點的方法是利用Adj R square來衡量,有興趣優化的朋友可以自己做做看。 這裡我們為了方便淺顯地說明模型,所以用R square的變化來說明模型的變化。但是有一個很重要的觀念就是,R square是很好操作的,有興趣的朋友可以看看綠角財經筆記:財務上的 R square偏誤。
隨機森林強大的地方還不只如此,可以藉由feature_importance查看變數重要性,意即重要影響價格的因子是什麼。這點在商業應用上非常重要,因為可以作為判斷「優化」的重要參考,好比今天知道程式刷新速度是最大的影響因子,我們就可以根據現有資源,思考是否優先調整刷新演算法來提升顧客體驗,進而優化數據指標。


畫出變數重要性前十名,這邊有觀察到什麼嗎?
另外我有特別做了cross validation,也是差不多的結果,但是時間會花蠻久的(我是用5折),而且電腦會有點燙,有興趣的朋友可以再自己嘗試,看會不會好一點,如果只是用筆電的朋友,可以用單純的模型就好。
XGBRegressor
如果不熟悉這個演算法的人,這邊有關於XGBoost的神話,以及簡單的介紹與鐵達尼號資料集實做。
我們也用從推出到現在都很夯的XGBoost來做做看,會overfit的更嚴重就是:
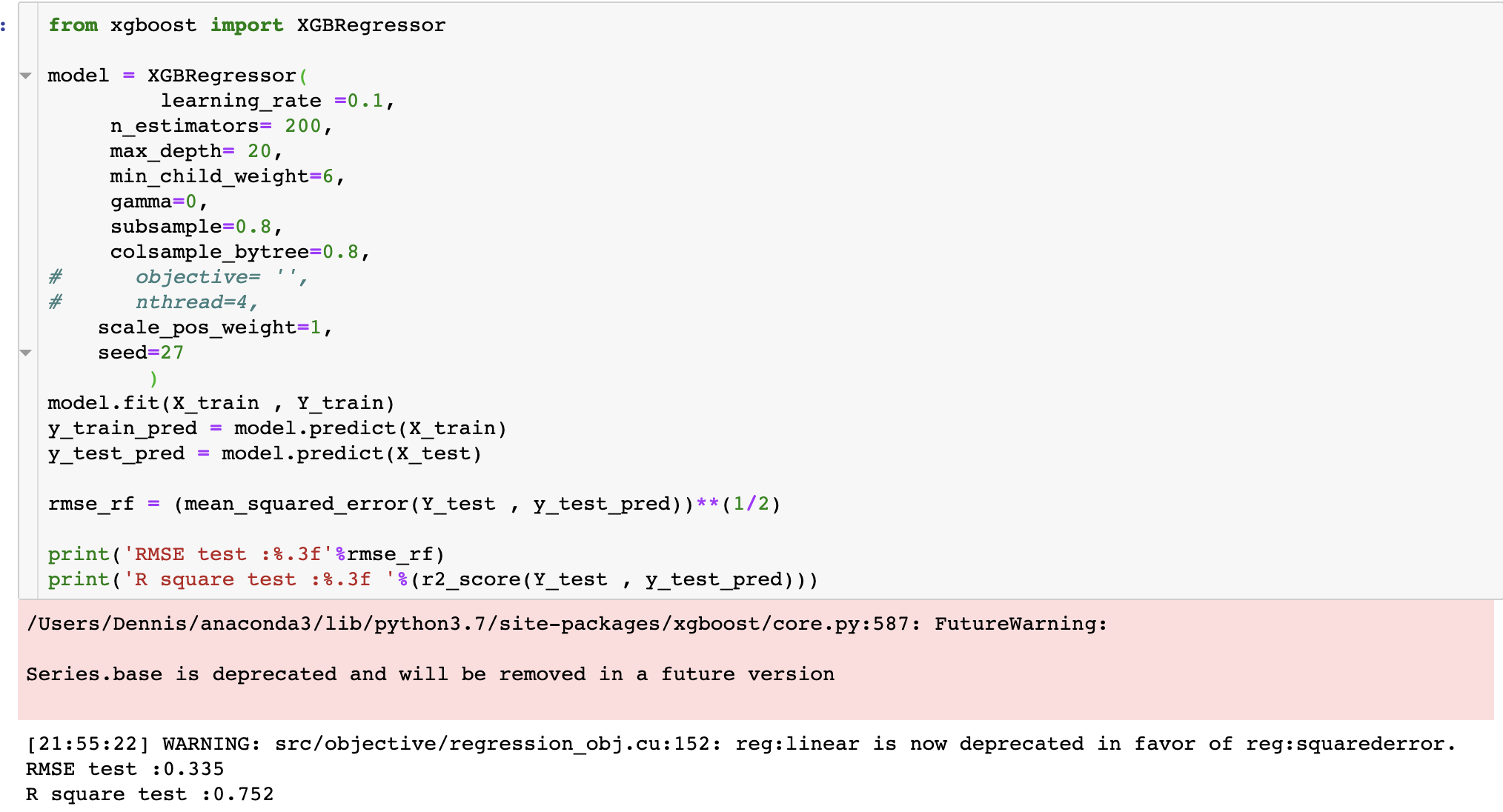

再看看,發現了什麼呢?
目前的model,可以發現說「accommodates」是一個影響蠻重要影響價格的因素,以及前面EDA做到的「room type」、「cancellation policy」、「property type」等等…,這些在前面我們並沒有做太多的特徵工程,所以這邊有一個想法是回去針對這些feature 根據領域知識來建立一些有用的特徵。
我們可以針對這幾個比較重要的feature多建立幾個特徵試試看,比如guest_included就可以根據我們的EDA,創建一個「是否為大通鋪(人多但是價格低)」的feature、根據領域知識創建「顧客停留時間的特徵」、收集更多關於城市的資料… 還有許多可以優化的地方。畢竟我們初步建立的模型只有73~75%的解釋能力,RMSE還是有0.335,說明更general的特徵是不夠的,還有可以放入的特徵,另外amenities這個變數感覺也可以好好利用,目前的想法是人工分類一下,抓大放小,好比「安全類型」(有智慧鎖、煙霧感測器之類)的放在一塊、「舒適類型」的(有懶骨頭之類)放在一塊…….蠻有趣的是我還有看到ev charger這個變數(電動車的充電),amenities真的有許多東西可以挖掘。
資料表格與洞察
我們將預測的結果,跟test data的label比較一下,sample這個函數就是從資料裡面抽樣:

以上則是預測 v.s. 真實的結果,看到model是高估比低估多一些,但是預測值減去真實值又是少於零,代表說有很誇張的高價離群值需要踢除掉(其實做EDA的時候看box plot 也知道需要好好處理非常多離群點的問題),可以用蓋帽法來應對看看,應該可以優化訂價模型。
另外畫出train、test,Train set 的R square高達95%,這表示我們的model學了很多不該學的特徵,overfit的很嚴重(主要是變數真的太多了,理所當然R²很高,有太多變數可以描述、「組合」出價格,當然資料太少也是一個因素),這感覺其實就像是我們給模型太多模擬題本,它幾乎把模擬考的答案都背下來了,換句話說,該學的東西有很多都沒有學到,雖然也有可能是有意義、有用的特徵不夠多。
必須想辦法增加有意義的特徵、剔除掉無用特徵才能增加model的泛化能力,amenities直接one hot encoding的副作用太大了。這邊是簡單起見直接這樣編碼,另一方面也是自己想看看有沒有對價格影響很大的物件變數,其實可以考慮剔除掉來做做看。
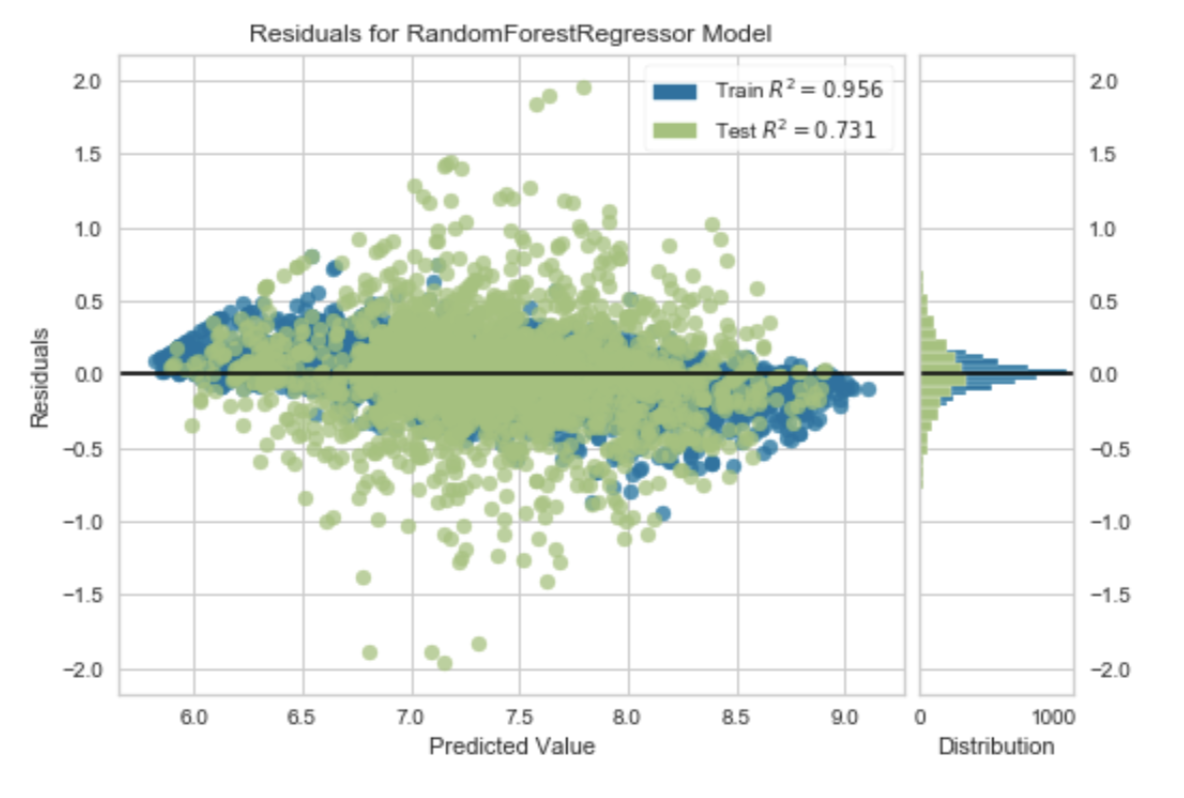
很誇張的過度配適
降低維度、減少特徵個數。我們的model沒有降維過,所以學到了許多奇奇怪怪的東西,這也是機器學習時要很注意的地方。
結語,還可以怎麼優化?
走捷徑,不一定能享受到探索資料分析的樂趣
資料科學的比賽上常常會有人一進場就直接做一個Tree model,根據特徵重要性來針對性地做EDA(Explore data analysis)。倒不如說如果真的要打比賽,這麼做是最有效率的方式。只不過這個Airbnb 分析是我的side project,比起建模我會比較想要多玩一點探索性資料分析的東西,實務上也會因為商業目的的不同,有不同的應對方式。
最後是機器學習的modeling上,其實還有非常多細節,而沒有降維過的資料就拿進模型去訓練是很容易overfit的(比如上面的隨機森林、XGboost)。另外,我自己在建模的時候並不一定會是這套流程(但是請務必先玩熟不同的資料科學庫,通常我會用好幾個針對machine learning modeling的library來輔助分析,上面我只有在modeling的階段簡單用了sklearn,但是實際上有更多好用又暴力的工具),這邊只是單純過一遍大致的流程,真的要做訂價的話,我大概會再多了解一些領域知識,利用這篇的方法,看書、訪談領域專家、上網閱讀,甚至直接找Airbnb發表的相關論文來看,都比直接用資料科學硬做的方式來得有效率。另外有人可能會問說都使用Ensemble 的model了,為什麼不做Stacking ?
這個就是蠻Tricky的問題了,最大的原因也是現實世界中企業走人工智慧的商業轉型時,做model沒什麼用的原因,有興趣的人可以自己做做看,您大概就會明白問題出在哪囉~
完整程式碼
<script src=”https://gist.github.com/Dennis055/c87a7951c19fdb9070a7dccb86744c33.js“></script>
文章出自 — Dennis Dsh,A Data Analysis Intern in E-Commerce。










